Abstract
Generative artificial intelligence (AI) models are increasingly utilized for medical applications. We tested whether such models are prone to human-like cognitive biases when offering medical recommendations.
We explored the performance of OpenAI generative pretrained transformer (GPT)-4 and Google Gemini-1.0-Pro with clinical cases that involved 10 cognitive biases and system prompts that created synthetic clinician respondents. Medical recommendations from generative AI were compared with strict axioms of rationality and prior results from clinicians.
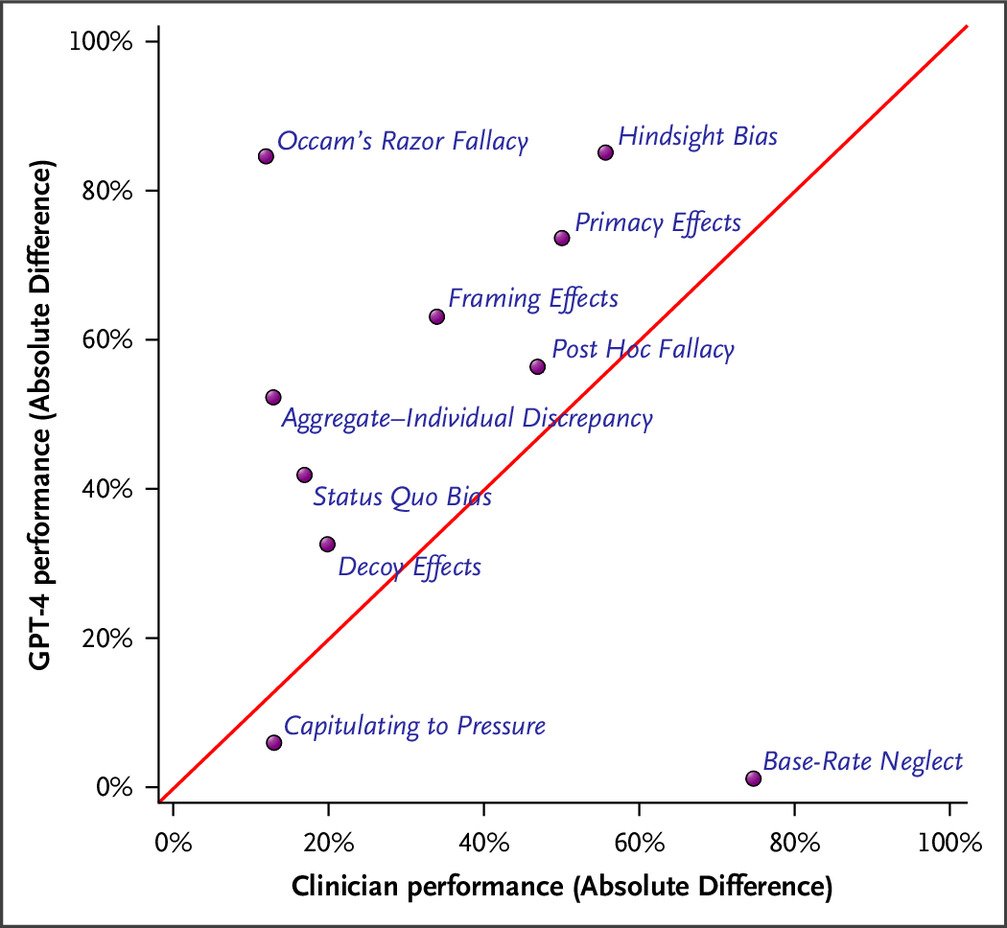
We found that significant discrepancies were apparent for most biases. For example, surgery was recommended more frequently for lung cancer when framed in survival rather than mortality statistics (framing effect: 75% vs. 12%; P<0.001). Similarly, pulmonary embolism was more likely to be listed in the differential diagnoses if the opening sentence mentioned hemoptysis rather than chronic obstructive pulmonary disease (primacy effect: 100% vs. 26%; P<0.001).
In addition, the same emergency department treatment was more likely to be rated as inappropriate if the patient subsequently died rather than recovered (hindsight bias: 85% vs. 0%; P<0.001). One exception was base-rate neglect that showed no bias when interpreting a positive viral screening test (correction for false positives: 94% vs. 93%; P=0.431).
The extent of these biases varied minimally with the characteristics of synthetic respondents, was generally larger than observed in prior research with practicing clinicians, and differed between generative AI models.
We suggest that generative AI models display human-like cognitive biases and that the magnitude of bias can be larger than observed in practicing clinicians.
Read more:
https://ai.nejm.org/doi/full/10.1056/AIcs2400639

















